Data Hub
The data hub is a tool helping gather data from Mirakl or an FTP client, to configure jobs, clients and mapping. You can connect your ERP tools with DJUST and automate the import of files (products, customer accounts, suppliers...).
From the data hub, you can configure three things:
Clients:
Bridge between the data on the server and your computer: they allow you
to bulk transfer and retrieve data easily through .csv files. You can
either set up an FTP client or go through a data provider (such as Mirakl).
Jobs: Process of updating your database with new data. Jobs can be run manually or automatically depending on the rules you define. You can also choose if the job is active or inactive, and if active, at which frequency the update needs to be done (daily, weekly, monthly...). Jobs can be run for specific data only (example: your product list filled with new products, but not the customer accounts list that did not change).
We recommend only running the jobs that are needed (i.e. for files you made changes on), especially if you have a big database. Updating the whole database every single time could take a long time to process and impact the performance of your website.
Mappings (import order status only): Set of matching rules defined to connect your data (product list, customer list, attributes, variants, accounts...) to the DJUST data structure so that when you upload your files, we know exactly where to implement the changes.
Clients
In the DJUST context, the client (FTP, API or Mirakl) allows you to transfer files to update the database of your e-commerce website (or marketplace) all at once. It also allows you to export some data from DJUST to your systems.
This is useful if you have a large database (lots of products, customers, offers, etc.) that changes on a regular basis. Using the client prevents you from having to do the modification manually and one by one from the DJUST back office.
For information on setting a Mirakl client up, contact your DJUST expert.
Configure the SFTP client
Before being able to configure a client in the DJUST back-office, you need to follow those steps:
- Request to your IT team:
- a web server
- an FTP user for the server
- Download an FTP client (DJUST recommends FileZilla (opens new window)).
- Connect your FTP to the web server.
- Create a
DJUST filesfolder within FileZilla. - Add your
.csvfiles to the new folder.
DJUST can assist you. Contact your DJUST expert for more information.
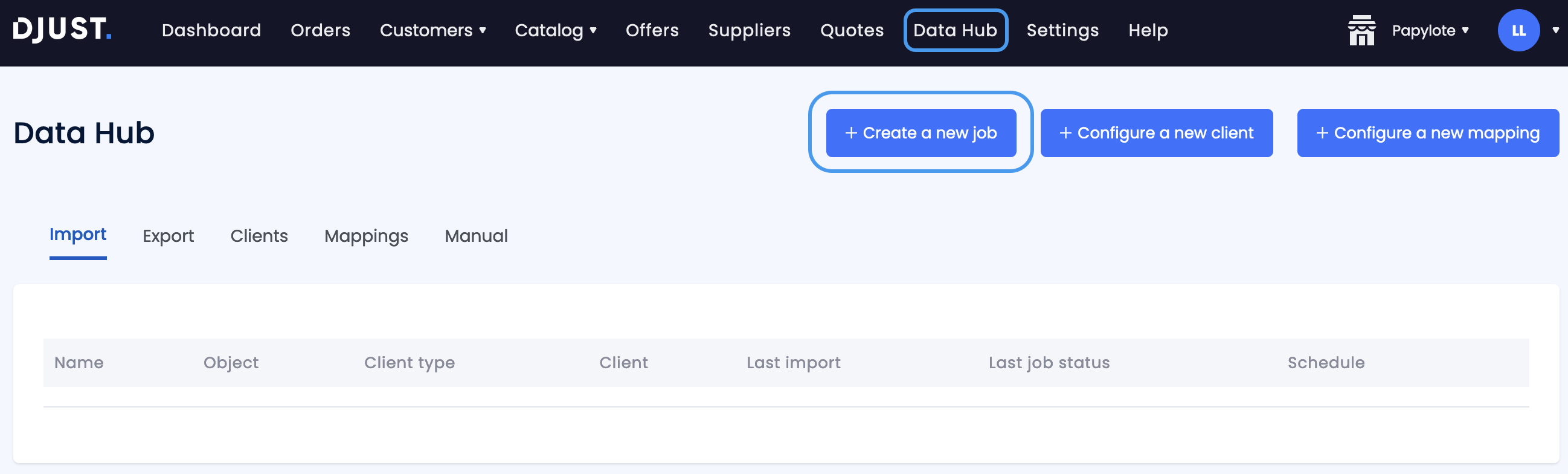
Go to Data Hub and click + Configure a new client.
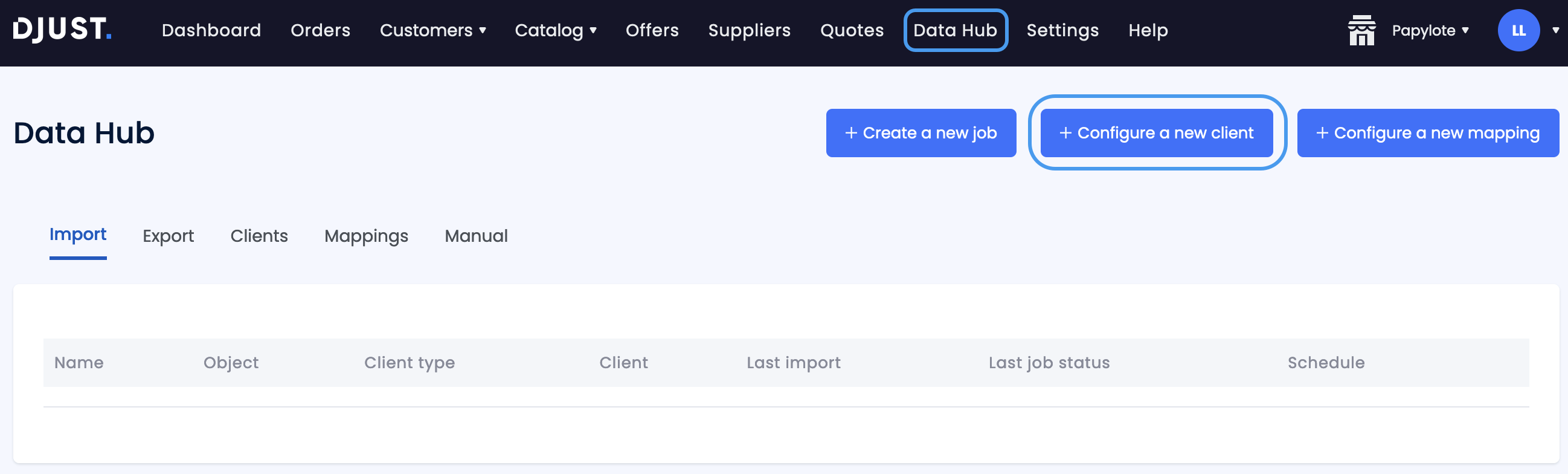
Select SFTP Client.

Fill in the fields using the information provided by your IT team.
- Connection name
- Host
- Port
- Username
- Password
- TLS (Transport Layer Security) is a cryptographic protocol used to provide secure and encrypted communication over a computer network. Activate the TLS toggle if you wish to encrypt your data.
Test the connection. If the test fails, ensure your entered the right information and/or investigate with your IT team.
If the test is successful, click Create.

Configure the API client
This feature is still in development and will be available in a future version. Contact DJUST for more information.
Go to Data Hub and click + Configure a new client.
Select API Client.
Fill in the fields:
- Connection name
- Base url (server's URL, e.g.
https://api.company.com)
Enter any required request headers (for example, authentication or authorization keys).
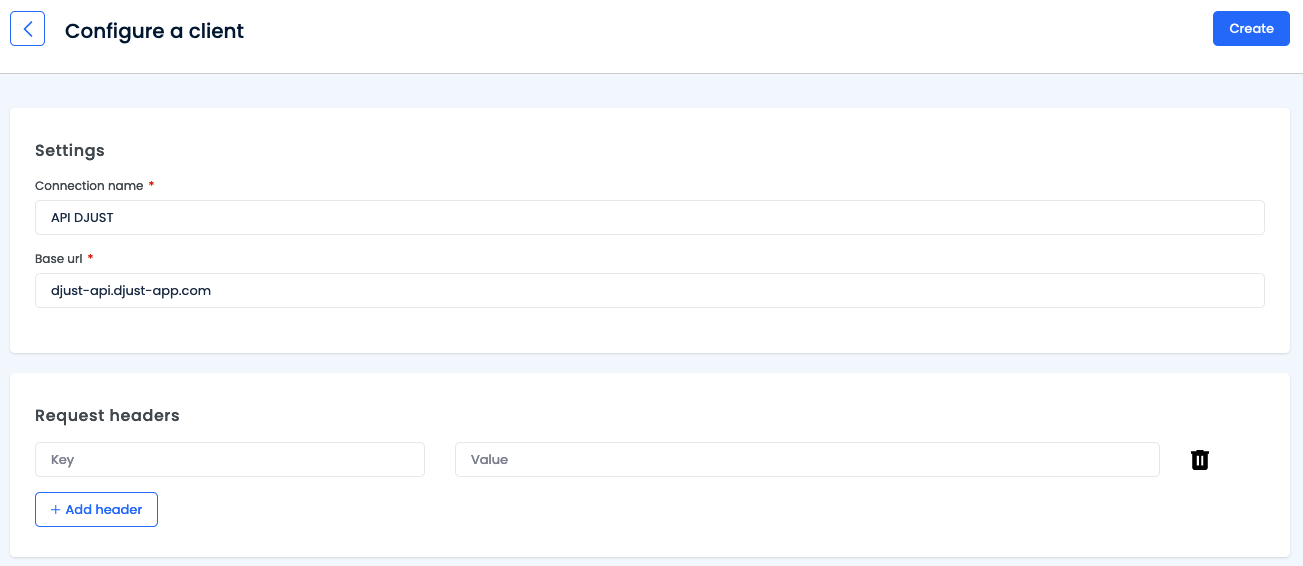
Click Create.
Mapping in Data Hub
A mapping refers to the connection between different elements or entities within a database. It defines how data from one entity is associated or linked to data in another entity. In the context of DJUST, mappings are the matching of one piece of information from your systems to DJUST’s structure.
Mapping can only be used to create an import of order status.
Click Configure a new mapping.
Select Order status.
Enter the corresponding status between your file and DJUST's column names.
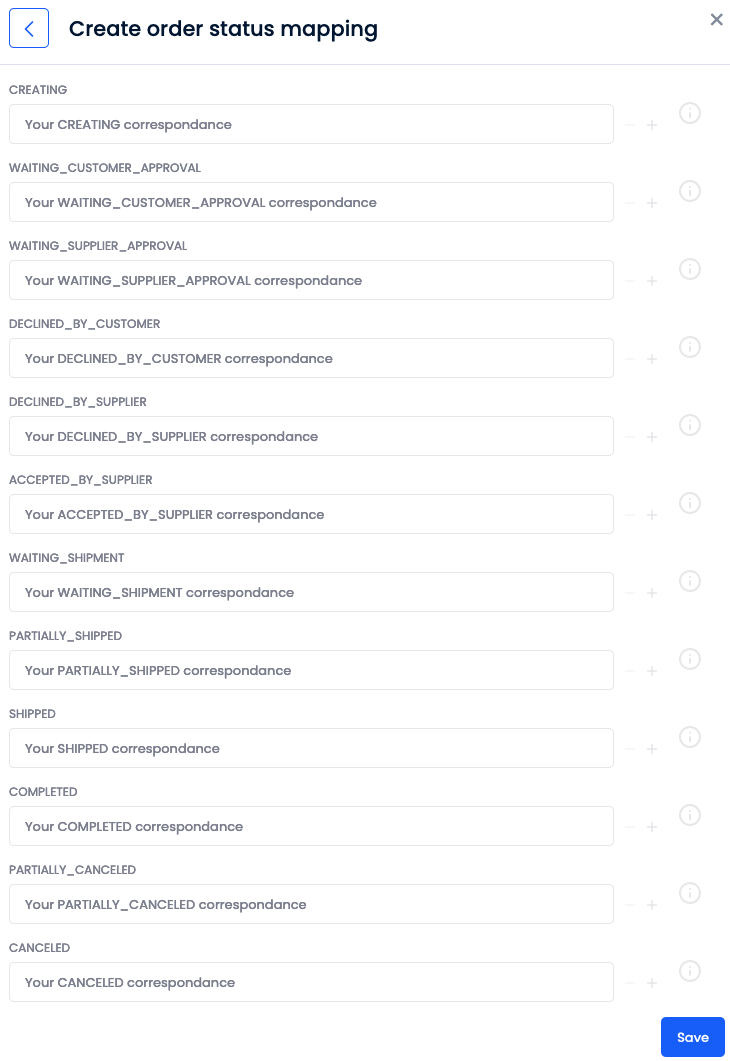
Click Save.
You can now either edit your new mapping (by clicking the cogwheel icon) or delete it (by clicking the trashcan icon).
This mapping will be used if you create a new order status import job.
Create jobs to import data
Jobs stand for cron jobs (Command Run On Notice). They are used for running scripts and commands at regular intervals, at specific times and dates. Jobs provide a very useful way to schedule tasks on your server.
Jobs are automated processes requiring .csv files formatted in a specific way
(with the right column names and consistent spelling) for to be able to compute
and update the right fields.
Using SFTP
Click + Create a new job from the Data Hub menu.
Select Import.
Select the element (
* csv) for which you want to create a job.Fill in the left side of the form:
Name (example: Daily product update, weekly supplier update)
Select a client
Choose if you want to bulk import. If yes:
- Specify an inbound directory
- Specify an outbound directory
- If left grey, specify the file path.
Choose a csv delimiter (: or ;)
Configure the frequency of the job:
Frequency Options Minutes Every X minutes Hourly Every X hour and X minutes
Or a specific hourDaily Every X days at a specific hour
Or every weekday at a specific hourWeekly Tick the day(s) for the job to run
at a specific hourMonthly Day X of every month
Or last day of the month
Or last weekday of every month
At a specific hourCustom Refer to this page for more information
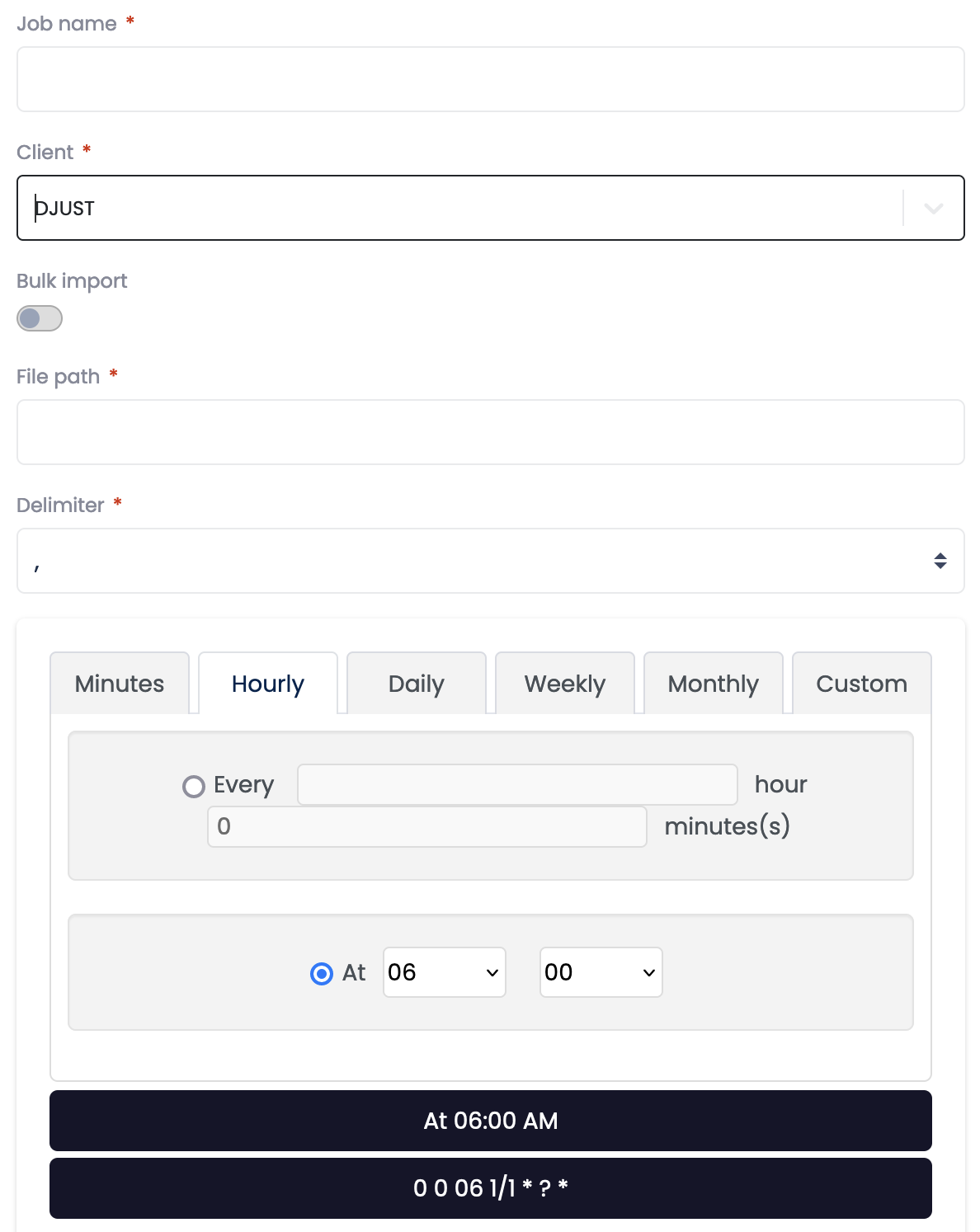
Add your CSV column names to the corresponding fields in the right side form. This form helps mapping the DJUST default names to match your csv's.
As each form depends on the selected element in step 3, find exhaustive documentation on each form here.
Using API
This feature is still in development and will be available in a future version. Contact DJUST for more information.
Prerequisites
Click + Create a new job from the Data Hub menu.
Select Import.
Select the element (containing
* api jsonin its name) for which you want to create a job.
Base information
Input the basic information on your import:
Job name
Configure the frequency of the job
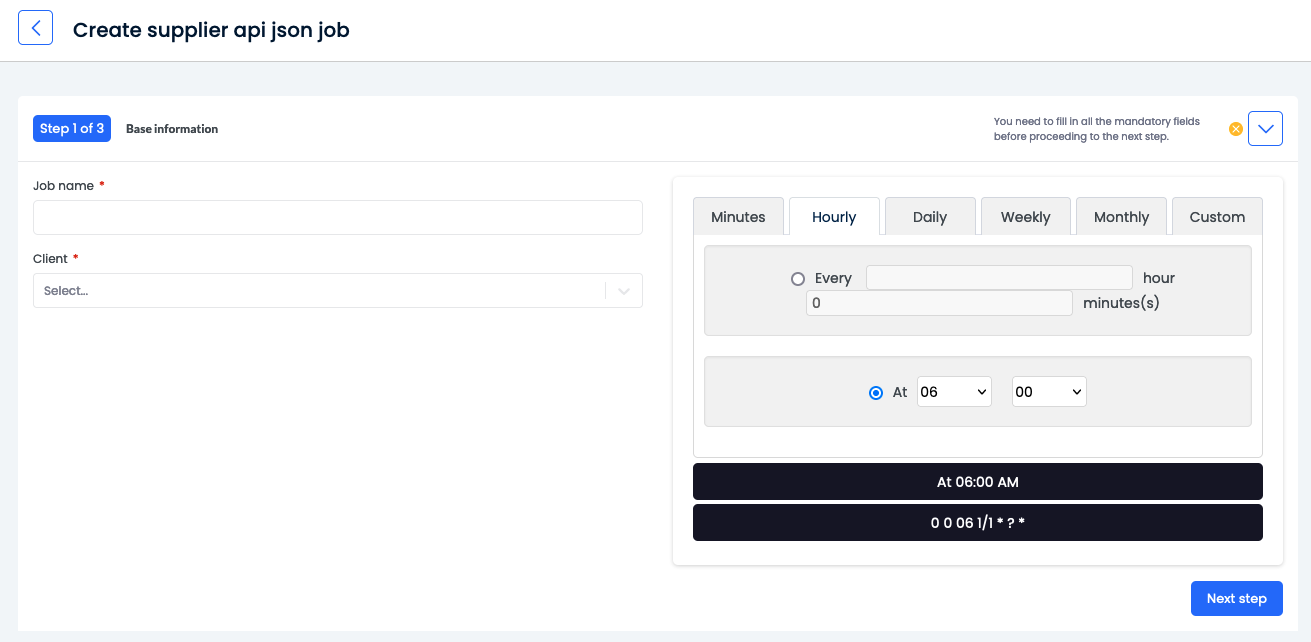
Click Next step.
Api calls
Configure the API job:
Configure the calls: add the URL template (endpoint) and select the method.
You can add more calls by clicking + Add a call. Each call is run sequentially. Refer to the chaining topic for more information.
Select the behaviour and fill in the parameters if applicable.
Path variables
Query parameters
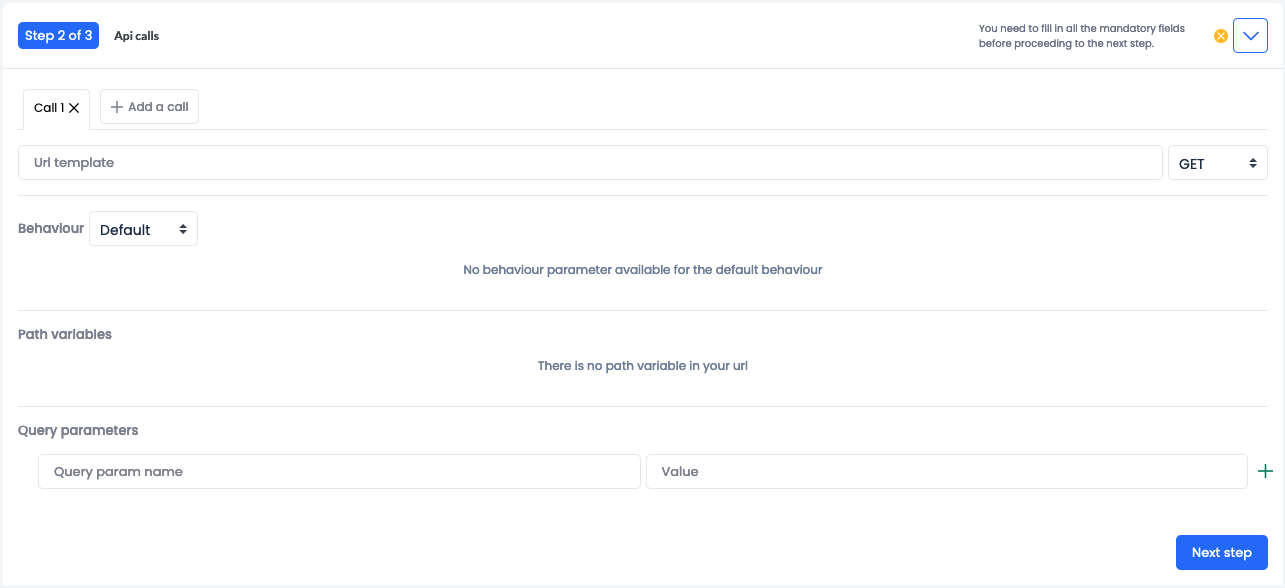
Click Next step.
Mapping
Map the fields from the data source to the DJUST data model: enter each corresponding field for the system to retrieve and match correctly the fields.
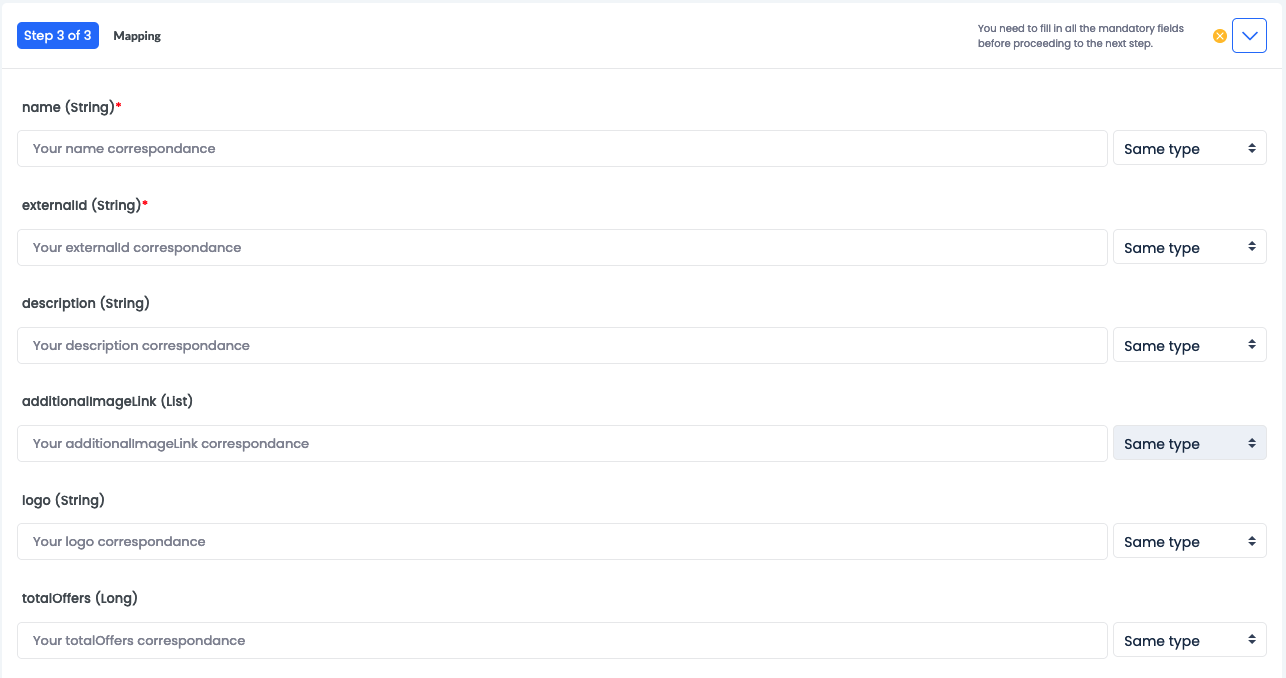
Example
In your system, you have a
Supplier reviewsfield, equivalent to DJUST'ssupplierRating: enterSupplier reviewsunder thesupplierRatingcorrespondance.Information
You can retrieve nested objects using the following system:
- Use
$>to retrieve a sub-object (e.g.$>addressesto retrieve a supplier's address). - Use
[0]>to retrieve sub-object in an array (e.g.$>addresses[0]>type). - Use
>to retrieve a sub-object that is not an array (e.g. ).
- Use
For each field, specify if the field is of the Same type or a Json value array (in this case, select if it is First or Concatenate to string).
Click Create.
Create jobs to export data
Only stream orders can be exported for now.
Click + Create a new job from the Data Hub menu.
Select Export.
Select Stream Order.
Select your client.
Input the path of the output folder.
Select the output type.
Click Create.
Indexing
Indexing is automatic. Information from the back-office that is transmitted to the front-office is automatically updated every morning at 4am, and offers are updated every 10 minutes.
To manually launch the indexing process, go to Data Hub:
Click the Manual submenu.
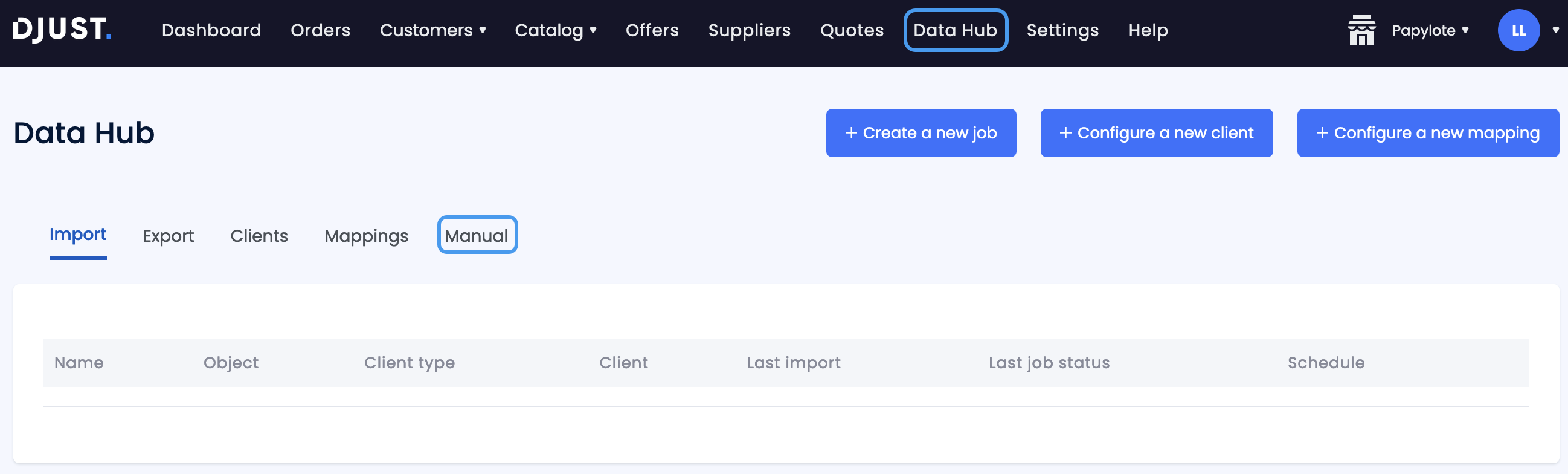
Ensure Full import is ticked.
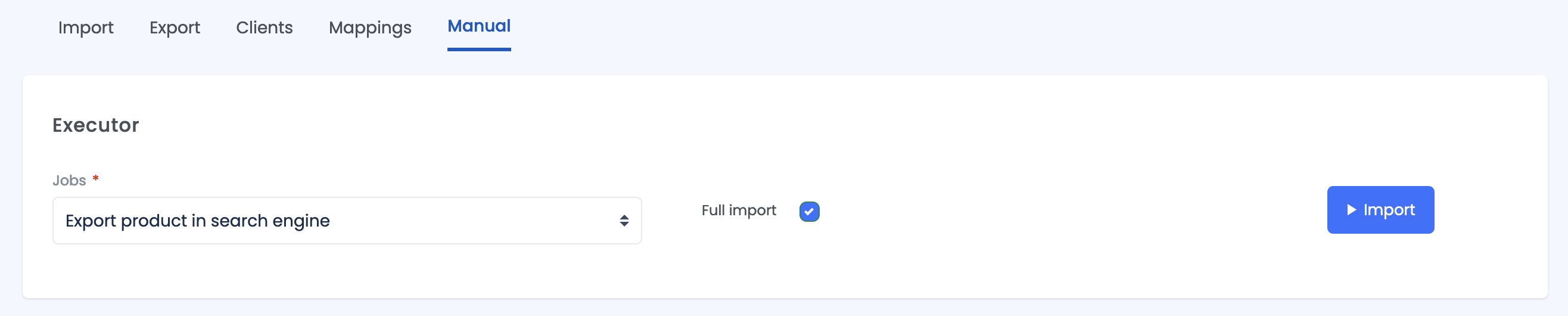
Click Import.
Make sure you wait for the job to run completely before relaunching.
You can decide to automatically index active offers with stock only, all offers, etc. Some customers prefer showing only in-stock products, some others choose to also show out of stock products for instance. Contact your DJUST expert for more information.